

인덱스란 RDBMS에서 검색 속도를 높이기 위한 기술로 테이블의 컬럼을 따로 파일로 저장하여 색인화한다.
해당 테이블에서 데이터를 찾을 때, 레코드들을 full scan하지 않고 색인화된 index file로 검색하여 검색 속도를 향상시킨다.
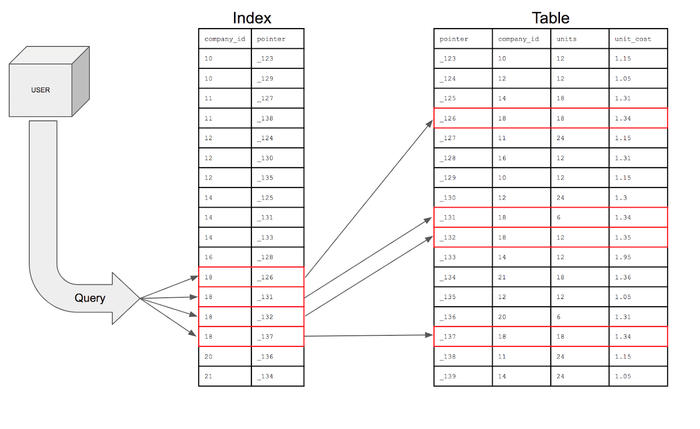
위의 그림을 예시로 들면, Table의 company_id에 인덱스를 걸면 company_id(특정컬럼)를 기준으로 정렬하고, DB가 쉽게 찾아갈 수 있도록 pointer를 같이 넣어 인덱스를 구성한다. pointer는 데이터를 INSERT 할 때 DB 내부에서 자동으로 생성하는 값으로, 해당 row의 고유한 주소 값을 가리킨다. 다른 컬럼까지 모두 인덱스에 넣어 구성하면 원본 테이블과 내용이 똑같아져 공간이 낭비되기 때문에 pointer만 넣어준다.
인덱스를 생성하는 이유는 pointer를 기준으로 데이터를 탐색할 수 있도록 유도하여 쿼리의 성능을 향상하기 위함이다. 실제 사용자가 인덱스를 생성하면 일련의 과정들이 내부적으로 알아서 작동하고 사용자가 직접 입력할 필요는 없다.
DBMS는 인덱스를 항상 최신의 정렬 상태로 유지해야 원하는 값을 빠르게 탐색할 수 있다. 따라서 인덱스가 적용된 컬럼에 INSERT, UPDATE, DELETE가 수행되면 아래와 같은 연산이 추가적으로 이루어져야 하며, 그에 따른 오버헤드가 발생한다.
◆ INSERT : 새로운 데이터에 대한 인덱스를 추가
◆ UPDATE : 기존의 인덱스를 사용하지 않음으로 처리하고, 갱신된 데이터에 대한 인덱스를 추가
◆ DELETE : 삭제하는 데이터의 인덱스를 사용하지 않는다는 작업 진행
인덱스를 사용함으로써 테이블을 조회하는 속도와 성능 향상, 전반적인 시스템의 부하를 줄일 수는 있지만, 인덱스를 관리하기 위한 DB의 약 10%에 해당하는 저장공간이 필요하고, 인덱스를 추가하기 위한 추가 작업과 잘못 사용할 경우 성능이 저하되는 역효과를 볼 수도 있다.
◎ 규모가 작지 않은 테이블
◎ INSERT, UPDATE, DELETE가 자주 발생하지 않는 컬럼
◎ JOIN, WHERE 또는 ORDER BY에 자주 사용되는 컬럼
◎ 데이터의 중복도가 낮은 컬럼
위의 예시들이 인덱스를 사용하기에 좋은 컬럼들이며, 인덱스를 사용하는 것만큼 사용하지 않는 인덱스는 바로 제거해주는 등 인덱스를 관리해주는 것도 중요하다.
인덱스에 관련된 글을 찾아보면 카디널리티라는 용어가 자주 등장하는데, 카디널리티는 무엇일까? 🤔
카디널리티란 한 컬럼이 갖고 있는 중복 수치를 나타내는 지표로써, 중복도가 낮으면 카디널리티가 높다고 표현하고 중복도가 높으면 카디널리티가 낮다고 표현한다. 내가 원하는 데이터를 선택하는 과정에서 최대한 많은 데이터가 걸러져야 선능이 좋을 것이므로, 카디널리티가 높은 컬럼을 우선적으로 적용하는 것이 좋다.
'💻CS' 카테고리의 다른 글
| [CS] DeadLock과 은행원 알고리즘 (1) | 2022.07.10 |
|---|---|
| [CS] DB 트랜잭션 격리 수준 (Transaction Isolation Levels) (0) | 2022.07.05 |
| [CS] Pub/Sub 모델과 MQTT(Mosquitto) (0) | 2022.06.26 |
| [CS] CORS? (0) | 2022.06.25 |
| [CS] Session vs Cookie (0) | 2022.06.22 |